Twitter Algorithm Review - part 5 - looking at the code
A descent into madness

Video here:
Today I'll be taking a look at Twitter's code to determine whether there's any heresy present or if the Machine God is pleased with it.
“author_is_elon”
My take is summarized in the meme:

Having something like "author_is_elon" is likely a consequence of some poor employee being afraid of losing their job. If they change the algorithm wrongly, it could result in a negative effect on Elon's engagement. This forces algorithm changes to always increase Elon’s engagement, which may not be in the best interest of Twitter or even Elon in the future. Thus, Twitter removed this feature, and I believe it's a good move. I don't think this was an act of the foul play of any kind.
Taking a quick look at this file again, it appears to be related to home tweet type predicates, likely used for debugging or A/B testing purposes. I would remove anything related to U.S. political orientation, but otherwise, the file seems ok.
Page Rank Negative Factors
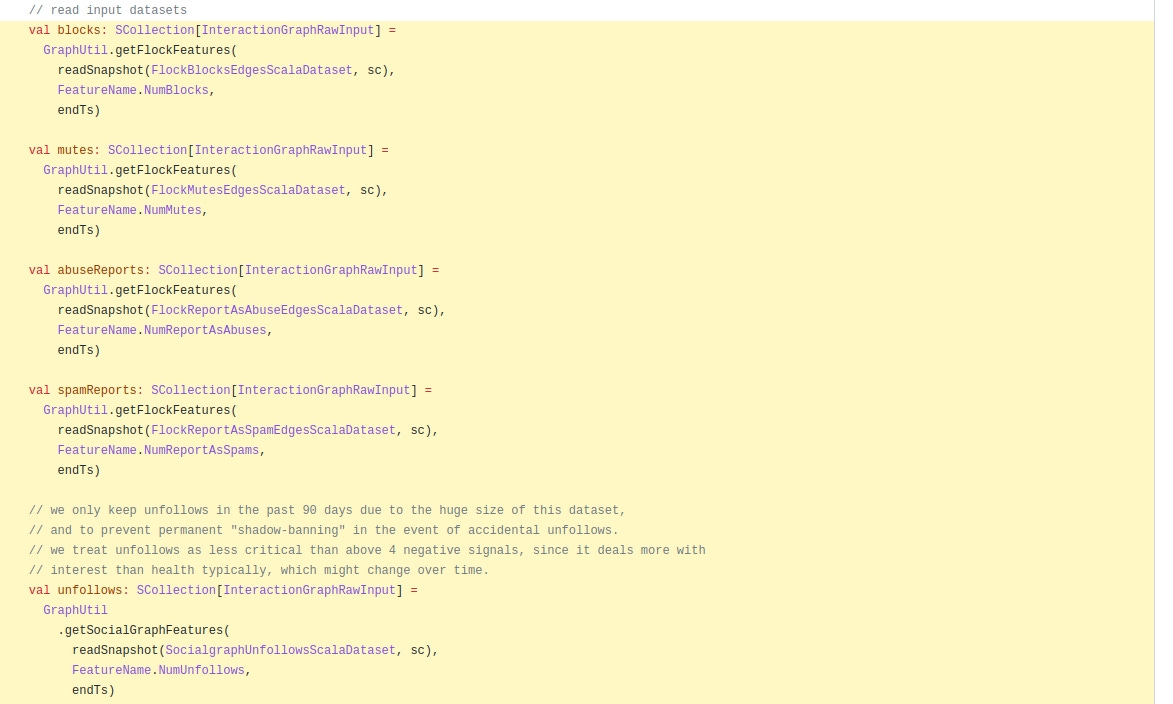
If I take a look at the algorithm blog, I can see that the real graph used is earlier in the pipeline. The page rank algorithm is downstream from the real graph, as stated in the real graph paper. The fact that they only keep unfollows in the past 90 days due to a large amount of data and to prevent permanent shadow banning in case of accidental unfollows is good.
Some people have pointed to this file as evidence that an account can be destroyed using spam or abuse reports. While I'm not sure if that's true if the page rank and personalization algorithms have been implemented correctly, this shouldn't be an issue. Page rank is designed to prioritize highly active users, and if personalization is working correctly, it should only matter if people in your network are blocking or spam-reporting you. The algorithm takes into account people who you follow, people who follow those people, and those with a high rank within your community. If Bots are blocking you, their page rank will be low, so it won't affect your ranking. However, this is all based on the assumption that the algorithms have been implemented correctly, which I can't confirm without reviewing the rest of the code.
There is also still the problem mentioned in the previous part if Twitter is capable of avoiding polluting their training data with their real graph training.

Polluting the training data means that effectively what could be happening is that there's a ranking system on Day 1 and Day 2, and every interaction is really driven by this ranking system. Then they train a new ranking system on Day 3 to predict interactions of the first ranking system from Day 1-2. This creates a self-referential problem, which can be solved by asking the right questions and framing the problem in the right conditional probabilities. However, Twitter doesn't talk about this at all, and it's unclear if they don't understand the issue or have already solved it. This problem can make a lot of the machine learning compute they're using useless or wasted. Assuming that everything is working correctly is a big assumption given a lot of these upstream philosophical problems.
Page rank adjustment
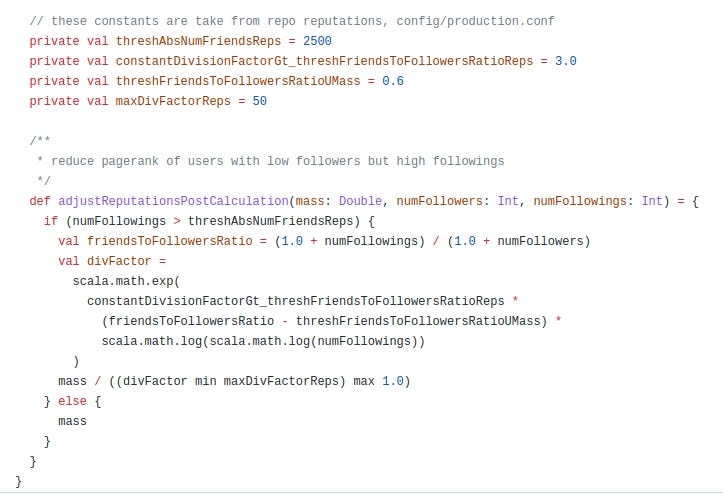
This adjustment reduces the page rank of users who have a low number of followers and a high number of followings (above 2500). It seems that users who have a higher ratio of friends to followers will be bumped down by some factor between 1 and 50.
I have mixed feelings about this adjustment. On the one hand, original PageRank had adjustments to discourage too many links, on the other hand, it seems strange to discourage followings.
It's important to consider the reasons why people might want to follow a lot of people on social networks. They might want to be well-informed about different topics or keep up with different communities. It might be worth considering increasing it to a more reasonable number, like 20,000 or 25,000. Ultimately, it's important to strike a balance between maintaining the integrity of the page rank algorithm and not discouraging users from using social networks in the way that they see fit.
Light Ranker vs Heavy Ranker
Note that the light ranker might be getting removed, but it’s not clear if any pieces of it might stay and make their way elsewhere.
It seems like the value of a "like" in terms of retweets and replies is not consistent across different parts of the system. While heavy rank may give more weight to replies than likes and retweets, other parts like Light Ranker may have a different ratio. This inconsistency makes it difficult to determine how much value a like has in comparison to a retweet or reply. It's almost like passing through gates in a game where each gate has its criteria and importance. To pass all the gates, you would need to have a lot of likes, retweets, and replies. However, without a consistent utility function, it's hard to determine how to optimize for all three. Looking at the code of the early bird light ring may shed some light on this issue, but it is important to keep in mind that this system may no longer be in use.
Let’s look at the overall features in light ranker:

So, when it comes to scoring tweets, some features are a bit confusing. It's strange that the scoring algorithm places such an emphasis on whether a tweet contains a link or not. Is this a penalty or a boost? This brings us to the question of what Twitter is and what it wants to be.
Twitter needs to decide if they want to be a destination or a portal or both.
If they want to be a destination, then they should penalize links and communicate this to users. If they want to be a portal, then they should boost all links. They could also be both, in which case they would be agnostic to the existence of links (except obvious spam sites).
But regardless of their choice, they need to be consistent, because inconsistency can be confusing and detrimental.
The Internet is built on links, not screenshots. Discouraging links and encouraging images is not being a good citizen of the Internet. (though other sites do it too).
The next big question is why there is an encouragement of trends and text reading in the first place. This is social media, not a search engine. Looking at some of the code in TweetTextScorer:
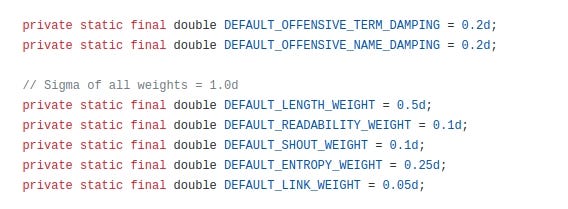
In my opinion, the idea of downgrading tweets that contain offensive words or mild levels of anger seems reasonable. Treating length differently is an interesting question, and somewhat debatable.
However, doing fancy things like “entropy” is very strange. They are effectively taking a deep philosophical stance on the nature of memetics and egregores without knowing they did so.
They could be making modifications in either direction, either destroying “novelty” in favor of “conformity” or destroying “conformity” in favor of “novelty.” Either one feels like something they shouldn’t touch and instead rely more on likes/retweets as collaborative filtering signals.
The vibe here is that they opened a portal to the Warp and don’t know why they did it. Machine God is not pleased.
Light Ranker Scoring function

Also repeated here
It seems that the scoring function used in this file is quite complex and may not be easily understandable. The parameters used in the function are all positive numbers, but some of them, such as the offensive boost, are likely negative changes. It's not clear how the parameters are being used, whether they are linearly combined, geometrically combined, or used in some other way to calculate the final score. I am going to guess the “LinearFeatureParams” are a linear combination and then the other ones are multipliers.
Retweets and fav have higher weight than replies, which is different from heavy rankers. The text score is pretty sketchy as mentioned above and should be removed. It’s unclear what “inDirectFollow” means. Are they finally doing what users want and giving them tweets from people they follow or is this something else entirely?
As I read through these proposed Twitter boosts, I can't help but feel like they are quite haphazard and inconsistent. On the one hand, they are encouraging the use of hashtags / trends, but then they are penalizing users for using too many hashtags / trends (this might just be 2 hashtags/ trends, but it’s unclear).
As for image and video boosts, I understand the appeal of wanting to highlight visual content, but it feels wrong to be so attentive to content.
If Twitter and Elon are serious about optimizing for “unregretted user minutes,” they should be encouraging careful use of space.
This once again means either being agnostic to the content OR discouraging large tweets / tweets with lots of images. Definitely don’t go the other way and encourage large items.
TL: DR: Twitter is for short things.
Whenever I see a function like this, I wonder how the numbers were decided upon. They were likely chosen through A/B tests, but I don't know how those tests were scored or what criteria were used. Without knowing the optimization direction of this code on society, it's hard to say what the impact will be. It seems like retweets and favorites count for a lot, while the text itself doesn't come for much. This is good as too much text reading is playing with fire. Additionally, it's strange to see that replies don't count for much, while in the heavy ranker, they count for too much.
However, the big problem I have is with tweetHasTrendBoost = 1.1
Why boost trends? Is it wrong for society not to talk about the same thing? Maybe it's okay for multiple groups of people to talk about different things on the site. Not everybody has to think of a trend. Boosting trends could create the notion of a "current thing," and this can potentially have negative impacts on mental health. People may feel swayed to only talk about the current thing, which could be detrimental to their well-being if they don’t have an informed opinion on it.
Many people complain that Twitter users consider themselves experts on all topics when they are not. While some ability for regular people to challenge experts is important, too many uninformed opinions are bad. The fact that Twitter puts massive algorithmic and social pressure to ONLY TALK ABOUT THE TREND is a massive social dis-service.
ALL MUST SUBMIT TO CURRENT THING, which has many negative effects on the quality of the discourse and the general hostility on the site.
All because of this one line of code.
Spam Function - descent into madness

Twitter's approach to fighting spam is flawed. The fact that this function is so simplistic is already concerning. Spam is a nuanced issue.
The function as a whole IS worse than useless. It penalizes new-ish users who post links (except news links), unless they have some count of like/tweets/retweets. The ENGAGEMENTS_NO_FILTER is 1, but it’s unclear how the double favoritCount is normalized, so it’s unclear what the actual cutoff of likes depends on. A dedicated spammer can easily beat this by having all of their bots like / retweet each other, while a new non-paying user trying to make friends is not allowed to EVER POST LINKS, except to news sites.
Blue-boost
Blue verified boost is being boosted by 4 in-network and 2 out of network. It’s an ok way to fight spam and try to reduce ads dependence. Note that this boost is in the home mixer, which is pretty far down in the pipeline. So effectively you still need to pass a lot of the other gates to get the boost. This means already popular accounts get a larger boost than smaller accounts from Twitter Blue. I don’t know if that’s what Elon intends.
Visibility Rules
Visibility code (and here) actually does a lot more than the blog claims:
What it claims:

What it does:
Filter out Tweets based on their content and your preferences and the preferences of the government. For instance, remove Tweets from accounts you block or mute or the government blocks or mutes.
The visibility code, especially the deprecated variables is basically a repository of the “Current Thing.” Elections of various countries (brazil, France, Philippines), covid19, covid19vaccine. Even project Libra (Facebook crypto) makes an appearance. India_Covid19 also has a special place elsewhere in the code for some reason
<sarcasm> So of course Twitter is a private company so they can do whatever they want. They are also an arm of the state, which ALSO means they can do whatever they want. </sarcasm>
In all seriousness, it’s unclear how to handle the situation of the government trying to control discourse by putting pressure on Twitter. If governments will always try to control speech, social media will have to provide consistent tools for them to do so within a proper legal framework. However, America doesn’t have a coherent way to think about speech control. Overtly controlling speech risks 1st amendment lawsuits, so instead the government does so covertly, as Twitter files demonstrate.
The general point of the code is that it’s a mess. “GeneralMisinfo” is mixed together with “UntrustedUrl” is mixed with “ViolenceHighRecall” is mixed with “ukraine…”
It is somewhat good to have a file with all the labels, but notions of precision / recall need to be different concerns from “topic concerns.” Otherwise, this all looks like backdoors inside backdoors.
Follow Recommendation Service

I am not a lawyer, but is this … legal?
If you are boosting both candidates for an office equally, you might be ok, but it can easily boost people un-equally due to other parts of the algorithm, thus creating an unregistered donation.
Overall, the code leaves me less impressed than the blogs / papers. There is a lot of political stuff mixed in with other concerns, reading and having a strong opinion on the text of the post is bad, and there is strange treatments of links. Lots of work would have to be done to fix this.
Unless of course, Elon pays me 42.069 million to rip EVERYTHING out and start over.
Hey Pasha, really enjoyed this post!
What I'm confused about is where in the pipeline the Light ranker vs the heavy ranker are used? It seems that the light ranker is used to evaluate the potential candidate tweets in the candidate sourcing stage, whereas the heavy ranker is then utilized to filter the aggregated list?