Twitter Algorithm Review Parts 2,3,4. Out of Network Tweets, Heavy Ranker and some Recommendations
let's fix this

Videos are here:
Edited transcripts are below
Out-Of-Network (part 2)
I feel a little strange about this because I've already mentioned that out-of-network takes up 50 percent of tweets on average. So, this number is way too high now. This isn't a problem with the out-of-network sources. They might be perfectly implemented. This is probably a problem with the ranking between them.
There are going to be recommendations for you to follow people who you don't want to follow. So, for new users, this is very helpful. If you only follow a few people, this is very helpful. But over-done in general.
They have two paradigms:
a) social graph. They have a GraphJet paper which is almost entirely an efficiency paper. There's very little information about what the underlying algorithm is. The only thing that seems to be kind of at the core algorithmic is the cosine similarity between two vertices.
So, if you are having a follow graph or an engagement graph, then you have engaged with similar users, and therefore, I might recommend you to this person if you don't follow each other. There's an interesting question between the dot product, versus the similarity as a whole. And this question is whether you kind of want to normalize the relationship between two users based on how many total interactions that they've had. I think cosine similarity is good in this case, but the whole GraphJet thing is smaller than the SimClusters.
SimClusters
I don't seem to have access to the Simclusters paper, but there is a video on that page. There is a custom matrix factorization algorithm, which Metropolis Hasting sampling. When I see a Monte Carlo algorithm like this, my initial reaction is to wonder about its stability and how reproducible its results are or if it gives different results based on a different random number generator seed.
From what I understand, the SimCluster is a way of grouping users into communities based on their interactions and followings. First, the algorithm looks at the top-level influencers and determines which ones are likely to be in the same community. Then, it looks at the followers of those influencers and determines which ones are likely to be in the same community as well. Based on these interactions, the algorithm assigns users to different communities with varying weights depending on their level of engagement with certain topics or interests. So, for example, a user might be 80% interested in football and 20% interested in machine learning, and this would influence their community assignment within the SimCluster.
They create a very large sparse vector for each tweet and then look at tweets related to all communities to make recommendations. If a user hasn't seen a particular tweet but it's being talked about by their community, the algorithm might recommend it to them. From what I can tell, there doesn't seem to be anything inherently wrong with this approach. However, it's hard to say for sure without more information about the algorithm and how it's being implemented.
Based on what it says, it seems like the algorithm is able to identify larger communities such as the pop, Hollywood, and news communities correctly, but it may not be as accurate in identifying smaller communities with less than 150 people.
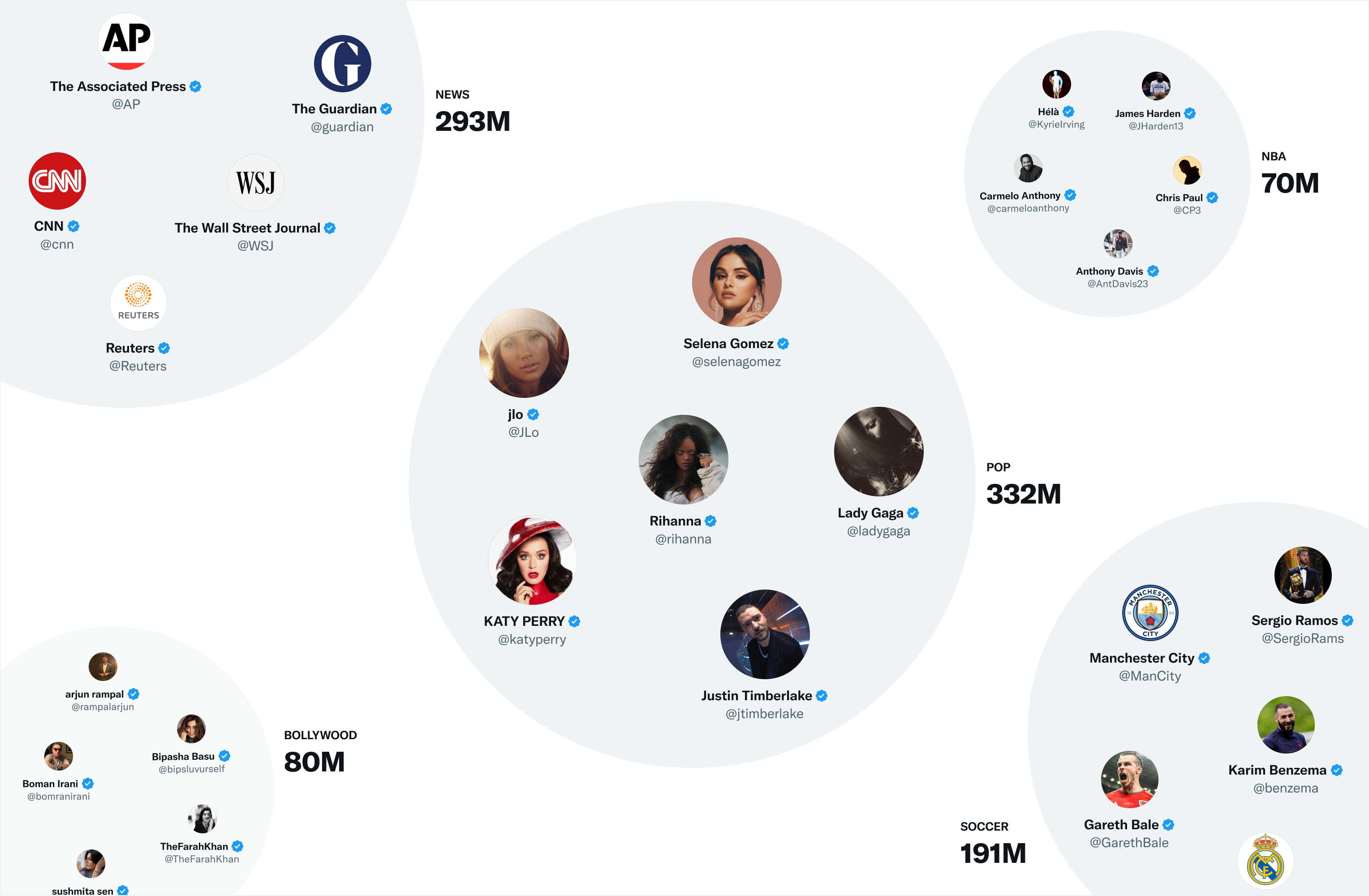
It's also unclear whether they have a training set with custom data for smaller communities, and if these communities are being picked up correctly
It's an interesting point about whether users in multiple communities are penalized or not. It would be helpful to understand how the algorithm handles users with multiple community memberships. If a user's vote card only counts for a percentage of a tweet based on their community membership, then it could lead to some users feeling like their opinions are not being fully represented. On the other hand, if a user's vote card counts for 100% of a tweet, then users in multiple communities could have a lot of influence on the platform. Overall, I think it's important to consider the incentives that are created by the algorithm and how they impact user behavior. If I follow Selena Gomez, does my vote / like count for more on the platform? It probably shouldn't.
Heavy Ranker (part 3)
I believe that the goal for your timeline should be to make society better, make you a better person, and improve social cohesion - not to destroy your mental health. If surfacing certain tweets helps achieve that, then that's great.

They are continuously trading on interactions to optimize for positive engagement: likes or tweets and replies. However, as I've mentioned before, we should treat retweets and quote tweets differently. There are different signals that we can use to determine which tweets should be shown first. For example, we could remove quotes from retweets and don't count them.
From the heavy ranker github:

Note “the final order is not directly the highest→lowest scoring”
What is this heavy ranker and why is it a factor? Assuming that the heavy ranker is good(a big if), how much change is there from the highest to lowest score? This seems like a bad patch on top of it. If the change is not significant, then maybe it doesn't matter, but if it's interleaving bad results with good results, then it's probably a bad idea. Twitter could be accused of optimizing for user engagement at the expense of user well-being and teaching people to doom scroll. Instead of giving you good results consistently, they might be giving you bad results in between the good ones to train you to scroll more.
I haven't personally seen any evidence of Twitter intentionally interleaving bad results with good results, but if the heavy ranker's output is vastly different from its original ranking, then it could be evidence of this happening, even if unintentionally. It's important to note that optimizing every tweet for engagement is different from optimizing the “timeline for engagement". Optimizing the timeline is likely to waste user’s time and fail on the unregretted user minutes.
Opinions of specific subsets of the heavy ranker:
"recap.engagement.is_favorited": The probability the user will favorite the Tweet. 0.5
Good feature, but the score is somewhat low compared to others
"recap.engagement.is_good_clicked_convo_desc_favorited_or_replied": The probability the user will click into the conversation of this Tweet and reply or Like a Tweet. 11
Good feature
"recap.engagement.is_good_clicked_convo_desc_v2": The probability the user will click into the conversation of this Tweet and stay there for at least 2 minutes.
This seems like an inferior version of the previous feature and plausibly capturing bad engagement or “doom-scrolling”.
recap.engagement.is_negative_feedback_v2": The probability the user will react negatively (requesting "show less often" on the Tweet or author, block or mute the Tweet author) -74
It’s important to track. The number is very large but it’s if this is a rare occurrence, that might be ok
"recap.engagement.is_profile_clicked_and_profile_engaged": The probability the user opens the Tweet author profile and Likes or replies to a Tweet. 12
I don’t think this is worthwhile at all. I don’t normally click on people’s profiles whom I already know. I think this is heavily favoring out-of-network tweets too much.
“recap.engagement.is_replied": The probability the user replies to the Tweet. 27
Good feature
"recap.engagement.is_replied_reply_engaged_by_author": The probability the user replies to the Tweet and this reply is engaged by the Tweet author. 75
Good feature, but it’s strange how high this is. I don’t really mind because it focuses on conversations, which is good.
"recap.engagement.is_report_tweet_clicked": -369
Worth tracking, very high penalty
"recap.engagement.is_retweeted": The probability the user will ReTweet the Tweet. 1
It’s strange why this is so low compared to replies. Also it needs to treat quote tweets and re-tweets differently.
"recap.engagement.is_video_playback_50": The probability (for a video Tweet) that the user will watch at least half of the video 0.005
strangely low, so probably doesn’t have a strong effect. minor bias for short videos.
Let’s go meta. Where do these numbers come from? What process decides them?
Based on my experience, it is common for numbers in software tools like this to be arrived at through A/B testing. This is a process where different versions of a feature or tool are tested on different user groups to see which version performs better. The numbers in this tool were likely arrived at through a similar process of experimentation and analysis. However, I cannot say for certain without more information about the development process for this specific tool.
I am hoping Twitter releases their A/B test criteria as well - what metrics do they use to decide between different versions of the algorithm (or these numbers).
Even the selection criteria for putting people into A/B tests, is a tricky problem. In search engines, it’s easy, just put some people into A, some people into B. In social, while it's possible that they randomly select users from different communities to try and get a representative sample, there could be unintended consequences if changes really affect community structure. Ultimately, putting a whole community into an A/B test would likely be the most accurate approach, but it would need to be done carefully.
And of course, there is always a question of how much the heavy ranker matter to the final ordering…
Ad-hoc post-ranker changes (Part 4)
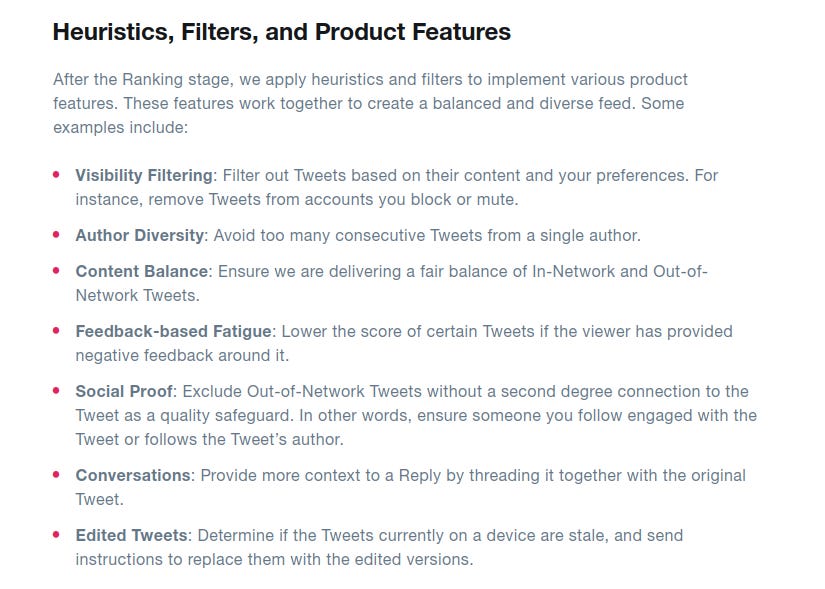
And a lot of these features are good things, but the fact that you have to have them is a bad thing.
Visibility Filtering:
Is used to filter out tweets based on the quality of preferences. Of course, you need to remove Twitter accounts that you've blocked or muted, but there's a question of why these tweets are even appearing as candidates for you. What exact features are bringing them up? If you block them, it's likely that some of the features which are bringing them as candidates are doing so in error.
Again, if this doesn't happen very often, then it doesn't matter. But if this is a thing actually ends up blocking a lot of accounts and tweets, then something is wrong upstream.
Author diversity:
While RealGraph seemed to penalize people who don’t tweet daily, this feature penalizes people who tweet too much in the same day. So the combinations of features seem to point to the cadence of daily tweets being optimal. I would rather see two tweets from the same author I know than out-of-network tweets, so I would tone down this feature.
Content Balance:
I don't know what decision they're making with this. Is it raising the in-network tweets or lowering them? If it's raising in-network tweets, then it's a good thing. But if it's lowering them, then it's just remove this feature.
Feedback-based fatigue:
Based on feedback from users, it seems good to lower tweet scores. However, I don't understand why they call it fatigue. This word doesn't make sense in the context of feature-based down rankings.
Social Proof:
So essentially, it only allows tweets from out-of-network with a secondary connection. If you're being recommended tweets from out-of-network that don't have secondary connection, something may have gone wrong upstream - maybe the network community discovered is too big or the heavy ranker is too biased against in-network. So, while this feature is good in theory, the fact that I have to use it frequently is not ideal.
Conversation:
It’s good to add replies to the originals. However, this begs the question of whether tweets or conversations ought to be object of ranking. If many of my mutuals are talking in a thread, maybe that’s worth showing. ML magic might be doing this, but if not, it’s an interesting change.
Edited Tweets:
sure
Somewhere, this is system is also changing tweet ordering and it’s unclear where that lies.
Recommendations to Twitter
There are questions Twitter to figure out about what it wants before trying to see what the suitable algorithm is:
a) Is Twitter a portal or a destination or both? It’s important to treat all links consistently in regards to ranking (the simplest way is don’t really care about links, use like / retweets only)
b) What frequency of use in terms of reads and writes does Twitter wants to encourage in its average / median user. Right now Twitter seems very biased towards daily active use of both reading and writing and this discourages many people who might not want to post every day. Moving to “daily read / weekly write” or even “weekly read / write” is likely more inclusive.
If you are Elon reading this, I can fix Twitter for you in one of two ways: the easy way or the hard way.
The easy way is for you to buy Trustrank from me, I’ll sell it for only 42.069 million dollars, less than 0.1% of Twitter's overall cost. Using this after some minor customization using the answers to above questions, you can replace the whole algorithm (RealGraph, graphjet, simclusters, light and heavyranker) with just TrustRank. No ML is required. This will have better incentives, transparency and likely have great downstream social impacts on mental health, social cohesion, and unregretted user minutes.
There are ways to test this before buying if Twitter API is functioning as before.
The hard way is to change your algorithm incrementally with the recommendations below.
Transparency:
a) Open source the a/b test criteria. If your criteria includes likes and re-tweets, this is good. If they include “time spent,” this is bad
b) figure out how much everything changes after the heavy ranker. If you are interleaving the bad and good results, don’t.
Smaller ideas:
a) Treat quote tweets differently from re-tweets (either don't count or they are negative engagement)
b) bump ML prediction models for Real Graph to interactions within a week rather than within a day
c) Don't use profile clicks as a feature in heavy ranker or Real Graph
d) don’t use (spends 2 minutes) as a feature in heavy ranker
e) allow more tweets from a single user, as long as the person actually follows that user
f) rebalance the heavy ranker / content balance to allow more in-network tweets on average
g) Figure out if SimClusters incentivize people to follow more celebrities or not (remove such incentives if yes).
Bigger ideas:
a) Use PageRank on the interaction graph, not just follow graph if it’s not already doing so
b) Create a new model that computes probability of follow and use it as a primary recommendation system for out-of-network
c) Score conversations as a whole, not just tweets (Or basically bump conversations if many in-network people are talking)
Stay tuned for actual code reviews next!