

New Prediction Market Design - what I call "Time Dependent Scoring Bets"
Part 2 of 2

Warning: new and original math ahead. See Part 1 for general ideas motivating this design.
There is a Haskell implementation here, but it’s going to be simpler to understand this first. The beginning focuses on a few simpler designs and the final part (System 3) is the new design.
First a couple other designs focused on modifying Scoring Rule Averaging. These are fairly simple, but I have not seen those explicitly specified anywhere, so had to discover them myself.
System 1. A prediction system simply asks everyone their probability. The creator simply pays out a subsidy proportional to scoring rule regarding probability. Roughly speaking each person marking predictions needs to get paid proportional to s(p), where s is a scoring rule. Market scoring rules are invariant under linear combinations, so there are a couple solutions:
Here:
w is the subsidy of the market
n is the number of participants
s(p) is the scoring rule given probability and outcome. In our case, we use a a scoring rule where higher is better (such as 1 - Brier Score)
m_u (w, p_u) is the payout of the user u given subsidy and p_u - probability they assigned to the correct result
System 1a = payoff = w/n (1 + s(p) – avg (s(p))). Or more precisely:

This assumes # of participants is > 1, otherwise the payout is w regardless of probability, which is not a proper scoring rule. This could be done by having the creator simply give the first probability. This also assumes 0<=|s(p)| <=1, which is true for Brier or Spherical scoring rule
System 1b = payoff = w * ( s(p) / (sum(s(P)) – s(p) + 1)).
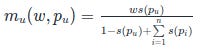
Again, this assumes a scoring rule bounded by 1. This works with 1 participant and the payoff is w *s(p_u) in that case. In general the total payoff will be smaller than w
System 2: A prediction system asks everyone their probability and bet. It aggregated the bets together with the subsidy and pays everyone in proportion to both their bet as well as a linear function of scoring rule. This is similar to system 1a In addition to previous formulas, we have the input of bet of each user
b_u, which is the bet of user u
t is the sum of all bets of all users
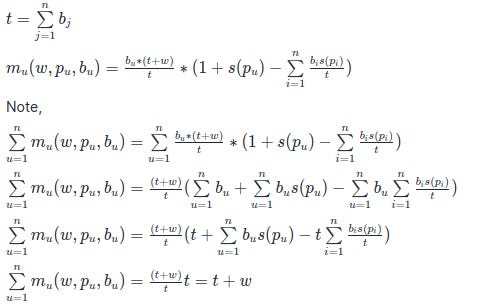
So, the total payout to everyone is all the bet put in + subsidy, which means this is a positive sum market with a proper scoring rule that allows bets without a counter party. Unfortunately, this is a situation which doesn't depend on time and everyone bets all at once. It's not obvious in this case how one could "cash out" the bet early either.
System 3 - what I am calling Time Dependent Scoring Bets
This is the new exciting thing!
TDSB incorporates time dependence, allowing money and probability at the same time. Unfortunately to make this work, I had to relax the constraint on outputting a single probability and output a range of two probabilities instead.
Here, we have a market state:
M = (P_1, P_2) with P1 <= P2, with some starting state of P0 = P1 = P2. Natural starting state is P0 = 0.5
subsidy = w, which is ALSO the first bet = b1
each other user specifies a bet b_u and a probability p_u
after the user makes a bet, we got from a market state
M_old = (P_1_old, P_2_old) to M_new = (P_1_new, P_2_new)
the market rewards users if they ended up moving the probability towards the truth

Note the following are still true:
a) This payout scheme still satisfies a scoring rule criterion
b) Payouts spend some of the subsidy. Note the final terms make sure the subsidy spent depends only on the final state of the market.
c) Payouts are never negative - betters already put in bet b_u
One could remove the last term of the sum to make the market potentially zero sum and thus allow the market maker to make money if P0 ended up being a better estimate than P_final.
In general, similar formulas would apply in the case of other scoring rules, with
s(p) is a scoring rule and g(p) is the inverse of s(p), so g(s(p)) = p and s(g(p)) = p
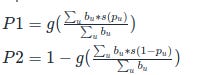
The above are what we get with s(p) = (1-p)^2 and g(p) = 1 - sqrt(p). Note, the bounds of payouts not being negative depend on s(p) being between 0 and 1, so there still needs to be research on whether this can be made work with s(p) = ln p. A simple, but perhaps unsatisfying way to do so is to limit how close to 0 or 1 the bets are allowed to get.
To get a feel for what's happening, let's examine the formulas:
The betters get their bet back along with the amount that they moved the interval towards the truth, specifically if the outcome is true, they are rewarded to how much they moved the lower bottom of the interval and if the outcome is false, they are rewarded by how much they moved the upper half of the interval.
The last bit of the formula is to make sure we spend as much of the subsidy as possible that also incentivizes larger bets regardless of probability. But this is optional, as it can create the situation where the betters make money regardless of one’s bet.
One should also be able "cash out" one's bet, although more research is needed to establish tight bounds
The major issue with this design is that if the person bets within the interval of P1 and P2, they are guaranteed to make some money, even if the expected value of how much they make is still smaller than if they bet on their "true" probability. Still this incentivizes betting without thinking through. One could disallow bets within the interval, which is a frustrating solution because bets within the interval make the interval tighter and the whole system more accurate. One could simply allow some arbitrage to have the interval tighten.
The final term can make it so that the betters still make money if the total amount of money bet is much smaller than the subsidy. Hence it somewhat depends on whether the market creator wishes to spend more money to incentivize participation or whether they wish to only spend money if the accuracy of the final probability was closer to the outcome compared to their probability. Given that subsidies are important, I suspect some form of the last term are vital.
Using s(p) = ln(p), if it can be made to work, has the opposite problem in that the bets within the interval are actually likely to lose money. This might be more desirable, since arbitrage is not allowed, however there needs to be some more research on exactly bounding the payouts.
There is another issue is that most of the time, quantities such w * ( (1-p_{1-old} )^2 - (1 - p_{1-new})^2)) , when negative are significantly smaller than b_u. So it's not a great design to bet $10 and your outcomes are $9 or $11. Effectively $9 has been locked in that could be used elsewhere. So, instead of we could calculate the maximum loss that one could incur and calculate the "virtual bet b_u" that would cause that to happen:
max loss = l
So in case probability of bet p > P2_old and we only want to lose max of l when the event turns out false, then we have:

Notably, here sum of b_u does not include the current bet. Similar formula applies for the reverse case of p < P1_old. So, max loss is constrained by w (p^2 - p_{2-old}^2)) or a similar quantity and one could only achieve that iff b_{effective} is infinite.
Now, if we require all b_{effective} to be infinite, then we get back to the same design as Robin Hanson's LSMR, in which each bet sets the probability to that amount. So this gives us a perspective on this design as something that it allows a loss UP TO what LSMR allows. In practice it's likely good to "cap" b_effective to a certain multiple of the subsidy.
So, this allows one a slightly different interface to the system, where one specifies a "maxLoss" amount and a probability, from which we get an effective bet and all the corresponding changes. Without the final term, the payout in case the probability was moved in the wrong direction is 0. The final term can also be modified to split the remainder of the subsidy (such as $$w * (1- P_{0}^2))$$ in proportion to maxloss, rather than effective bet.
However, several difficulties and some degrees of freedom in the implementation, this scheme now fulfils desiderata 1-6 above
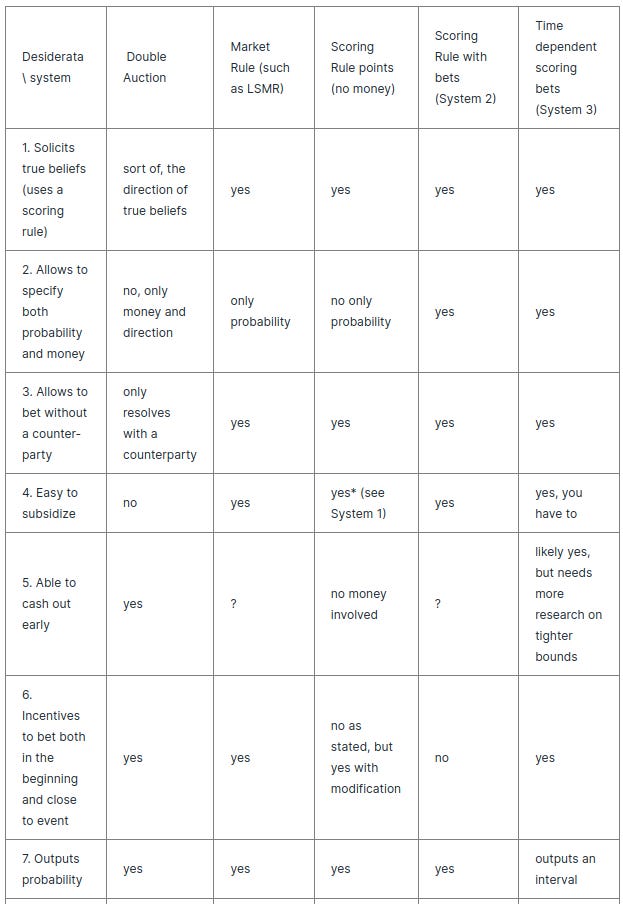
Desiderata 8 (“no arbitrage allowed”) can be fullfilled based on whether the market designer wishes to not allow bets within an interval.
So, here we go, we have a new prediciton market system!
There are still a few rough edges to smooth out, such as understanding the ability to cash out and tweaking the final term for distributing the rest of the subsidy, as well as testing out how it works with different scoring rules.
However, the signicance of this is pretty high. We have moved prediction markets from something that depends on irrationality towards a market where one can participate even if one doesn’t have the best average information.
There is now a natural subsidy in play and you specify your actual probability, which means you actually have to think about your actual probability. So, even in attempting to use the market, one needs to think carefully about the event in question.
Other open questions in theory:
a) How much subsidy is enough to overcome the issues of being worried one's information is not the best?
b) Is there a way to incorporate the uncertainty over probability as part of the market?
This is Jaynes' A_p distribution or meta-probability by Chapman
In a sense, the prediction market already solicits estimates with a narrow meta-probability curve, however this might attract people overly confident in their estimates.
This could be fixed if one could automatically bet on multiple probabilities in the last system however the implications of this need to be studied. In particular one would need to find a "meta-scoring" rule which would incentivize one to bet on the full meta-probability distribution rather than on the average. This is similar to betting on ranges of continuous variables, so should be doable in theory.
c) Is there a natural way to incorporate previous prediction power with current estimates? Weighting predictions by quality of previous predictions improves the final estimate according to Super Forecasting. This directly conflicts with financial weighting, so it would have to be some system which combines prediction points as both financial instruments as well weights on the prediction.
Open questions in implementing this in the real world:
How could the prediction market get larger subsidies from people how can use the information? In other words, it might be important to hook up a crowd-funding mechanism to the prediction market subsidy.
We could see a generic information market where people contribute to a question being answered and get the answer first and the actual predictions are private to the general public and non-sponsors. There are a lot of details to work out, such as minimum contribution, establishing a value for the information for each person through something like an auction mechanism.
A challenge with many markets is that they are fairly long terms and money tends to devalue or fluctuate in price over the scale of 1-5 years. This is the case both for subsidies and regular bets. What this means is that people betting in the market need to also contend with the issue of money not growing in some other investment *in addition* to issues of potentially betting against other people. This could be fixed with some sort of automated investment that the participants can agree on, but is still tricky. Price fluctuations are also a problem if the prediction market is denominated in crypto currency.
However, the idea of being able to combine paying money for people’s estimates of events with betting is likely a very important ability for future mechanistic designs of truth-finding.